In earlier posts, we explored value-based methods like Q-learning and Deep Q-Networks (DQN). These algorithms focus on learning a value function and deriving a policy from it. But what if we flipped the script?
Enter Policy Gradient methods, where we directly learn the policy without needing a value function. One of the simplest and most foundational algorithms in this family is REINFORCE. We will look at its working and how to implement it on Cartpole.
1. What is REINFORCE Algorithm?
REINFORCE is a Monte Carlo policy gradient method that updates the policy in the direction of actions that lead to higher rewards. It’s intuitive, powerful, and provides the foundation for more advanced policy optimization algorithms like PPO and A2C. The loss function that we need to focus on is as follows:
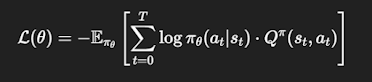
Where:
-
-
: expected return (estimated using Monte Carlo return in vanilla REINFORCE)
2. What is Policy Gradient?
Policy Gradients define the direction in which we need to change our network's parameters to improve the policy in terms of the accumulated total reward.
3. How is it different from Q-Learning?
- No exploration policy have to be defined like epsilon-greedy.
- No replay buffer is used as it is an on-policy method.
- No target network is required.
4. The Cartpole Environment
The CartPole-v1 environment is a classic control problem widely used in reinforcement learning research and tutorials. The objective is to balance a pole on a moving cart by applying left or right forces.
The state space consists of four continuous variables: cart position, cart velocity, pole angle, and pole angular velocity.
The episode terminates when the pole falls beyond a certain angle, or the cart moves out of bounds. A reward of +1 is given for every time step the pole remains balanced, encouraging the agent to keep the pole upright for as long as possible.
5. The Training Loop
- Collect one full episode using the current policy.
- Store state, action, and reward at each step.
- After the episode ends, compute Monte Carlo returns as estimates of Qπ(st,at).
- Accumulate batches of 4 episodes before training.
- Update the policy using the REINFORCE loss as mentioned above.
The Network: A simple 2 linear layer network has been used. Output of the last layer is passed through Softmax to get the probability distribution of the actions. - Play: A batch of 4 episodes are collected and their reward estimates or q-values are calculated as follows.
- Train: Training is done, and loss is backpropagated till convergence.


It takes around 200 min for convergence on my GTX 1650 card.
7. Conclusion
The REINFORCE algorithm provides a foundational stepping stone into the world of policy gradient methods. It teaches us how to optimize policies directly based on experience and how gradient ascent can drive agents toward rewarding behavior.
While it may not scale to complex environments on its own, REINFORCE builds the mental model needed to understand everything from PPO to AlphaGo. Thank You and Stay Tuned.
Comments
Post a Comment